- Published on
Activation Function in Bi-Directional LSTM
- Authors

- Name
- Fadjar Irfan Rafi
Introduction
This is my bachelor's thesis, part of a collaborative research program with my lecturer. At the time, my university's computer science faculty was launching a collaborative research initiative to encourage students to do and develop research that would be applied as thesis material.
There are a number of themes to pick from, but Natural Language Processing (NLP) caught my attention and seemed like an intriguing topic.
Natural language processing (NLP) is a branch of artificial intelligence (AI) that enables computers to comprehend, generate, and manipulate human language. Natural language processing has the ability to interrogate the data with natural language text or voice.
The Problem
After researching study for several weeks and reading several scientific publication references and directions from my mentor, I decided that I would investigate effects of activation functions in Bi-LSTM for Text-Based Emotion Recognition. Why BiLSTM?, BiLSTM models are popularly used in text processing such as text classification, sentiment analysis and also machine translation.
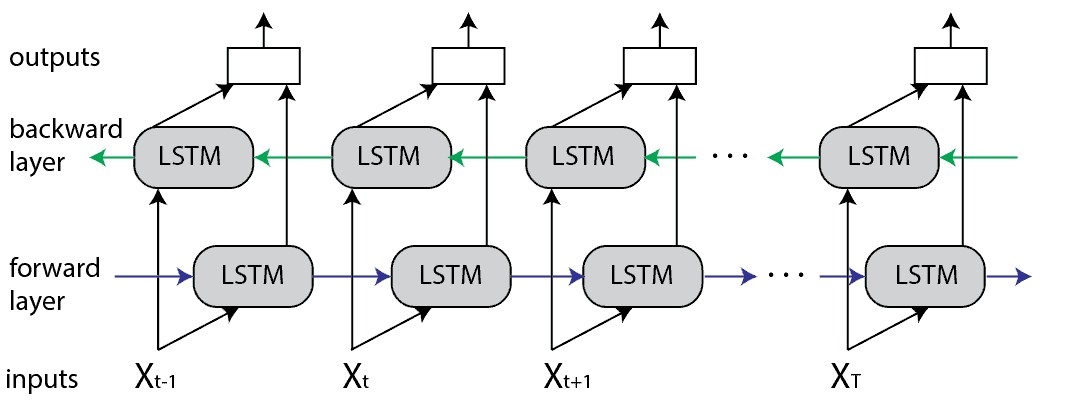
In light of this, my research's primary question is
What is the impact of activation functions on BiLSTM models?
Designing Research
Therefore, in response to those inquiries, my mentor and I developed a research flow comprising a literature study, the building of a BiLSTM model, an evaluation of the model's performance, and a comparison of the accuracy level of the models.
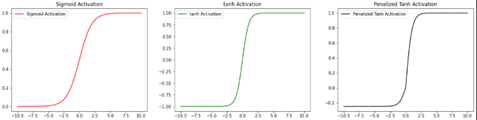
On the bilstm layer of the architectural model I created, I will compare the application of three activation functions: Sigmoid, Hyperbolic Tangent (TanH), and Penalized TanH.
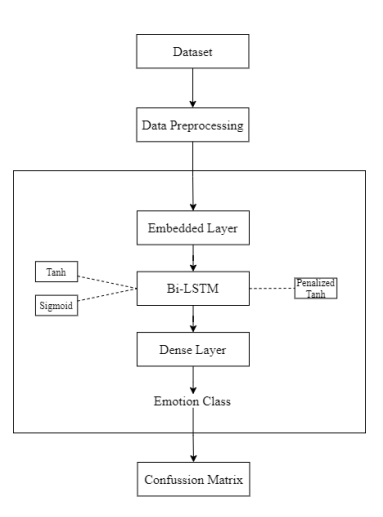
The architecture for text-based emotion classification includes text input, Embedded Layer, Deep Network (Bi-LSTM), Dense Layer, Output Layer (Softmax) and Emotion Class.
During my research, I use of open-access datasets from Emotion Classification on Indonesian Twitter Dataset. 5 emotion labels that serve as a guide for recognition are included in the dataset: anger, happiness, sadness, fear and love.
Alright, I got the architecture model and activation function now. It's time to tweak the deep network layer's parameters to improve the architectural model, a process known as hyperparameter optimization. I used method called Random Search to find the optimal hyperparameter, that include: the number of networks in the hidden layer, the number of hidden layers, the optimizer and the learning rate.
Also i used Adam Optimization Algorithm with 0.001 learning rate and added a Recurrent Dropout to each of hidden layer to avoid weight spikes in my model architechture. Prior to model training, early stopping was applied with parameters delta 0.1 and patience 7
The Result
After i created 3 models for each activation function with same hyperparameter, i run the training for my model with configuration: 50 epoch and a batch size of 256. To evaluate my model, i used a Confusion Matrix to comparing 5 emotional label with reference to accuracy.
| Layer | Output Shape | Parameter |
|---|---|---|
| Embedding_1 | (None, 50, 400) | 7817600 |
| Bidirectional_3 | (None, 50, 358) | 830560 |
| Dense | (None, 5) | 325 |
The training results show that tanh has the highest test accuracy between sigmoid and penalized tanh. Meanwhile, sigmoid has the lowest accuracy on the test data. The penalized tanh is between sigmoid and tanh with a difference of 2.12% with tanh. Below Comparison of Test Model Accuracy on Fataset
| Sigmoid | TanH | Penalized TanH | |
|---|---|---|---|
| Test (10%) | 56.88% | 62.03% | 59.91% |
In the model with the penalized activation function, the accuracy of training did not increase using validation data after the 6th epoch. Meanwhile, in the model with the activation function tanh, the accuracy of training was decreased using validation data in the 6th epoch. The sigmoid activation function experienced a decrease in accuracy in the 9th epoch.
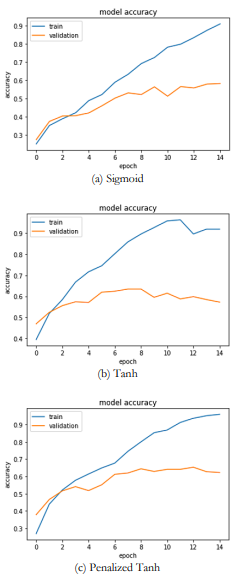
The decrease in accuracy of the sigmoid activation function was due to the output value of the sigmoid was not focused on the value 0. This factor causes the value that enters the neuron is always positive and the gradient on the weights is always positive or negative, which results in irregular changes. Below comparison between true false in Confussion Matrix on each emotion:
| Layer | Output Shape | Parameter | Parameter |
|---|---|---|---|
| Love | 88% | 75% | 77% |
| Anger | 36% | 59% | 42% |
| Sadness | 71% | 64% | 74% |
| Happy | 74% | 79% | 62% |
| Fear | 25% | 38% | 43% |
The Conclusion
From my research showed that the use of different activation functions such as those used in this study of sigmoid, tanh and penalized tanh on the BILSTM hidden layer indirectly affected the accuracy rate of models used for text-based emotion recognition with the results of accuracy in each sigmoid, tanh and penalized tanh activation function being 56.88%, 62.03%, 59.91%.
But this research still opens up many opportunities for future research. The BILSTM model used still shows overfitting when doing training. Therefore, it can be done to improve the architectural model more optimally.In the deep learning approach, regardless of optimal use of the model, the number of datasets greatly affects the level of accuracy produced. Such as the use of datasets with larger numbers including datasets with a balanced number of each label.
Thanks for Reading✌️